Transformers - Part 2: Training models
Creating a crappy Google translate
10/13/2023
In a previous post, I detailed my comprehension of the paper "Attention is all you need" (arXiv link). Using the transformer code presented in that post, this post describes the code how I trained a transformer to translate english sentences to spanish sentences.
For code specific to discussion points, I've created Github gists and have embedded their displays in this webpage. The full repo of code that I actually worked in can be found here.
Data collection and preparation
The most important part of any data science/machine learning project is the data. Always remember: a good model will never fix bad data. Considering this, I'll admit that I wasn't very thorough when I selected my dataset for this project. I grabbed the first english-spanish sentence pair dataset I found and decided it wasn't such a big deal if I understood the data deeply since I just wanted to see if I could get a transformer to learn something. If this was a real task and people were depending on the results, I would have spent the majority of my time focused on understanding the dataset instead of toying around with different model parameters. Anyways, the dataset I used can be found here.
I decided to use pre-trained token embeddings for the english and spanish tokens. I did this partly because I didn't understand embedding layers when I started coding the transformer, and partly because I figured pre-trained embeddings would make my transformer learn quicker. In retrospect, I'm not sure if that assumption was valid and I wish I had written my code in a more modular fashion so that I could test out how the transformer performs when it learns the embeddings itself. I found word2vec models here and opted for the text file download containing the direct mapping between words and their vectors.
I changed the formatting of the downloaded word2vec dictionaries with a small script. This script makes a simple csv file in the format of "word,vector" and this format is assumed later when data is loaded.
Next, I reduced the size of the word2vec dictionaries. The downloaded dictionaries were several GB in size and contained tokens that were not found in the dataset. This notebook removes all tokens from the word2vec dictionaries that are not present in the dataset and removes all rows from the dataset that don't contain words in the word2vec dictionaries. I don't feel the need to go through the details of that implementation here. There were 111,184 rows in the dataset remaining after this reduction.
I wrote several functions to transform the raw string data into embedded and positionally encoded input matrices. Most of this code is found in preprocess.py. The logic and reasoning for each of these functions is explained in the previous writeup.
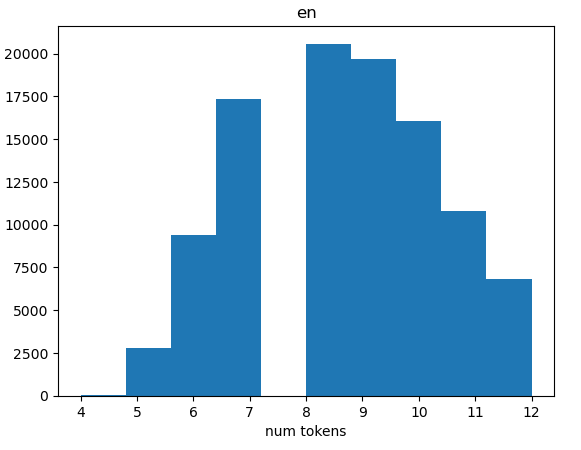
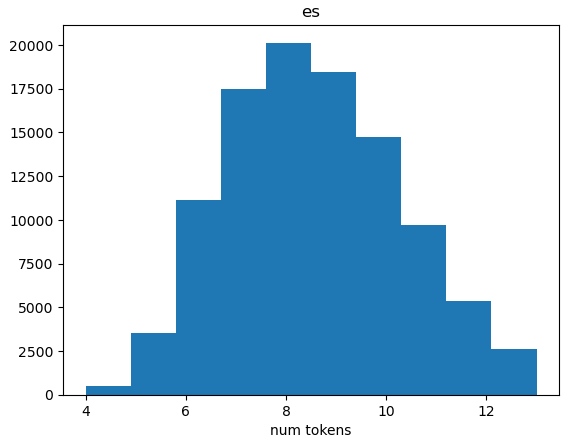
I decided to drop all rows of the dataset that contained more than 13 tokens in english and 14 tokens in spanish (I did 1 more token for spanish to account for double punctuation). These numbers were decided somewhat arbitrarily based on the distribution of number of tokens. The resulting dataset has 97,443 rows and an approximately normal distribution of number of tokens.
Model experiments
I trained several different models with varying parameters. Each model was trained for 20 epochs. Each training epoch consisted of passing the entire training dataset through the transformer in batches, and then performing inference on the entire testing dataset in batches. A single epoch took about 25 minutes on my PC (i7-12700K CPU with 3.60 GHz base clock, 12 cores, 20 total threads; NVIDIA GeForce RTX 3060 with 12 GB GDDR6). So, it took a little over 8 hours to train each model. Conveniently, I sleep about that much every night (and I don't use my PC to sleep).
A quick side note:
According to a few ~reliable leaks (here and here and other places that I've seen), GPT-4 was trained on over 10,000 (maybe 25,000) NVIDIA A100s for 3-4 months. I can't seem to find a concrete price tag for the 80 GB version of this graphics card and it looks like you have to manually contact NVIDIA sales to get a consultation of sorts (i.e. I probably don't qualify to own one and definitely can't afford one), but it looks like most estimates are in the range of $8,000-$15,000. So, let's just call it $10,000 per card. That gives a total GPU cost in the neighborhood of $100e6-$250e6. Now, "Open"AI has some sort of partnership with Microsoft, so they probably got a sweet discount, but still. Do you have $100e6 to buy GPUs with? And an additional $50e6 to employ 500 skilled people? And idk, probably another $50e6 for the physical space required to house the GPUs, employees, and to cover all of the intermediate expenses involved in doing so? Oh, and don't forget that power bill. So, who gets to control the future of AI (and by philosophical extension, humanity)? Hint: it's not "we the people." Realistically, there are only a handful of organizations/corporations/entities on this planet that control enough capital to even afford the current state-of-the-art AI. Hmmm, really makes you wonder, who does AI regulation really protect?
"Our mission is to ensure that artificial general intelligence benefits all of humanity." The AGI hype is fear-mongering, a distraction from the reality: an opulent minority wants to monopolize a cool new technology and make everyone on the planet dependent upon it. Nothing new here.
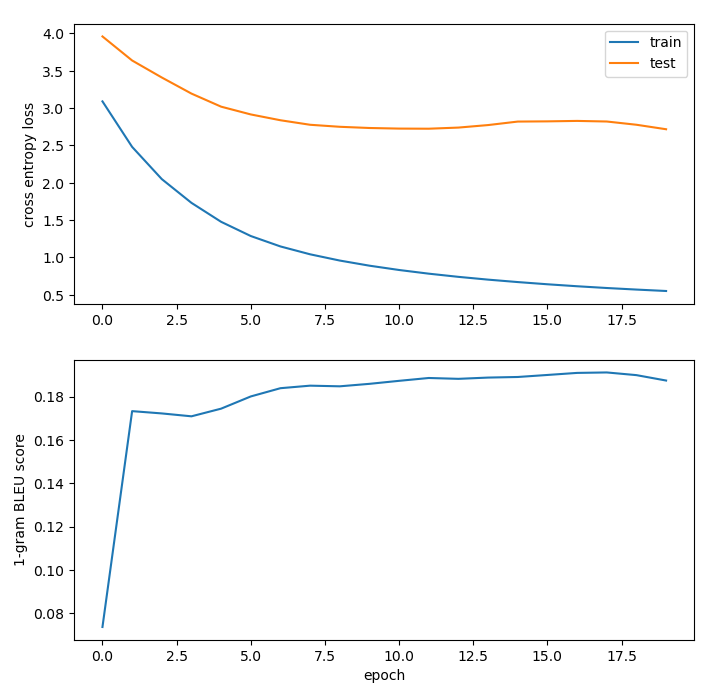
Anyways, I evaluated the loss on the training and testing datasets and calculated the 1-gram BLEU score after each epoch for each model trained. The parameters changed across models were the batch size, number of heads in the transformer (h), number of encoder/decoder layers in the transformer (N), train/test split ratio, model hyperparameters, and dropout + label smoothing. In the series of graphics below, each model is an iteration on the previous model displayed (i.e. I changed one parameter at a time and then retrained to see performance differences).
The first model fit used a 90/10 train/test split, h=1, N=1, batch size of 128, default Adam optimizer parameters (as defined by PyTorch), and no dropout + label smoothing.
The next model used the same parameters as the previous, but with h=4 and N=4.
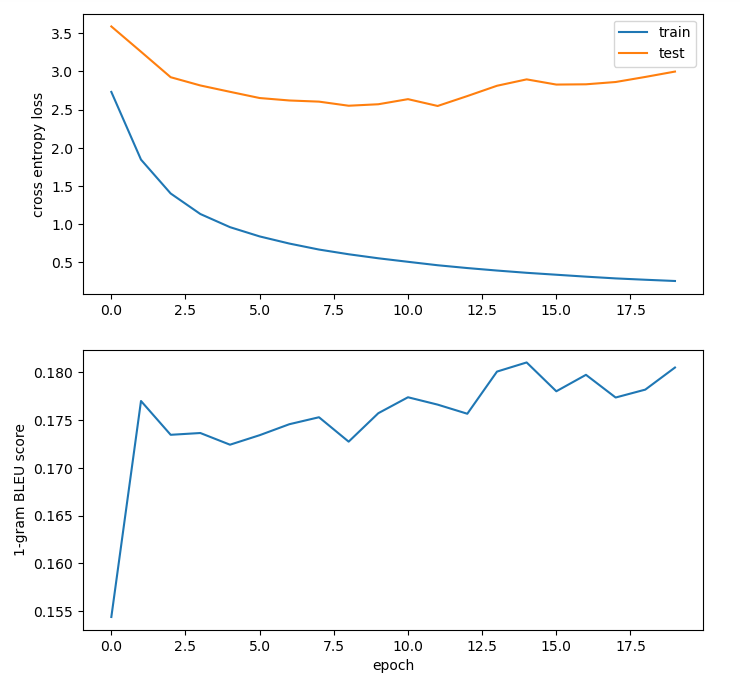
As N and h increased, I quickly began to run into the memory limits of my graphics card, so I decided to just stick with N=1 and h=1 for the rest of the modeling experiments.
The next model used an 80/20 train/test split. I was curious to see if the model would overfit less. It seemed to just take longer to converge to the previous train/test loss values obtained as the 90/10 split models.
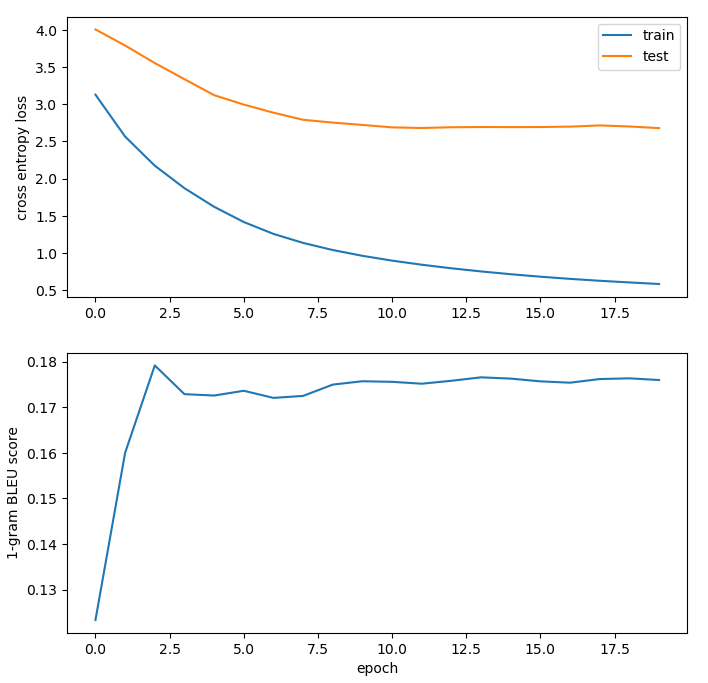
Next, I changed the Adam optimzation parameters to those provided in the paper. The parameters listed in the paper are smaller than those used by default in PyTorch. As expected, this led to a slower convergence to previous train/test loss values obtained. The 1-gram BLEU score also obtained a new high around 0.19 (to be fair, this was barely higher than the previous max of ~0.184).
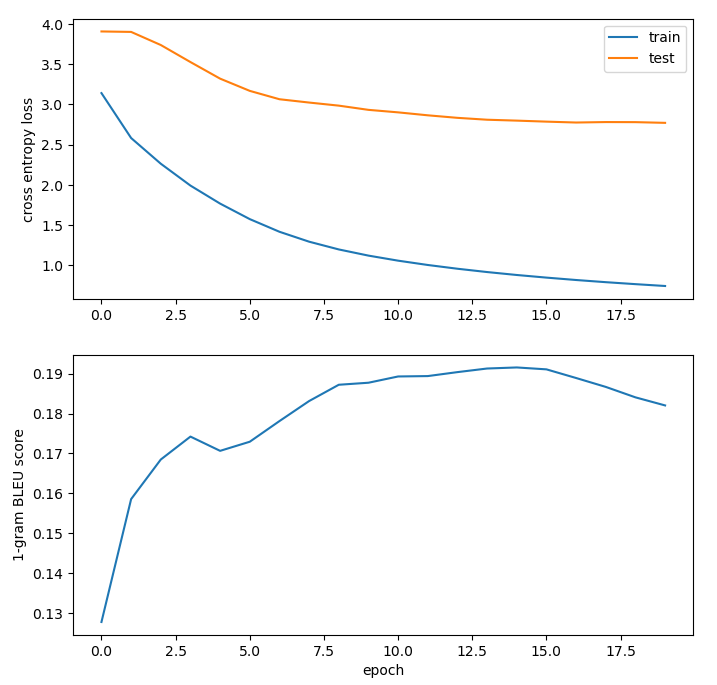
Next, I increased the batch size to 256. I hoped that this would lead to less overfitting. It appeared to decrease the difference between train and test loss a little bit while attaining a similar 1-gram BLEU score.
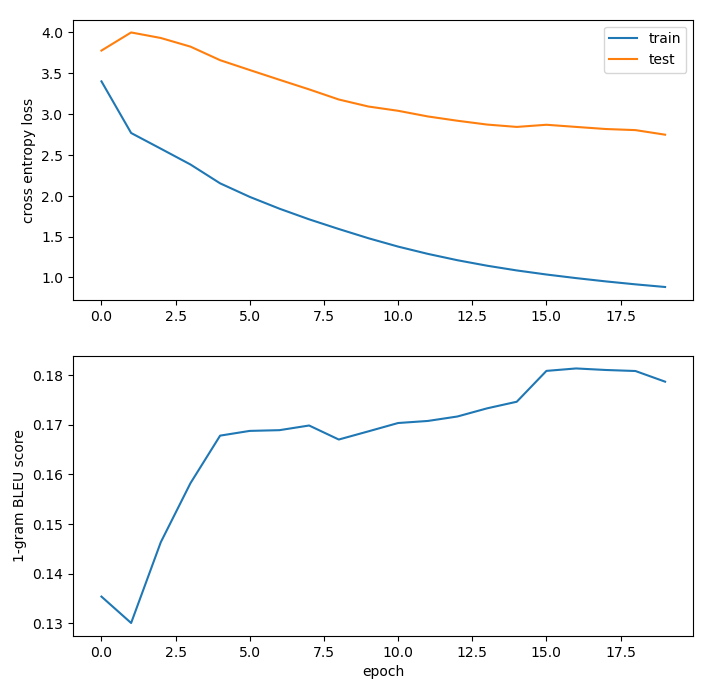
The last iteration included dropout + label smoothing (used in the paper). I expected this to be the best model fit because I figured these changes would lead to better generalizability, but the results didn't suggest improvement over the previous model. I was especially confused by the early 1-gram BLEU score of ~0.19 followed by a dropoff and an expected increase as seen in previous models.
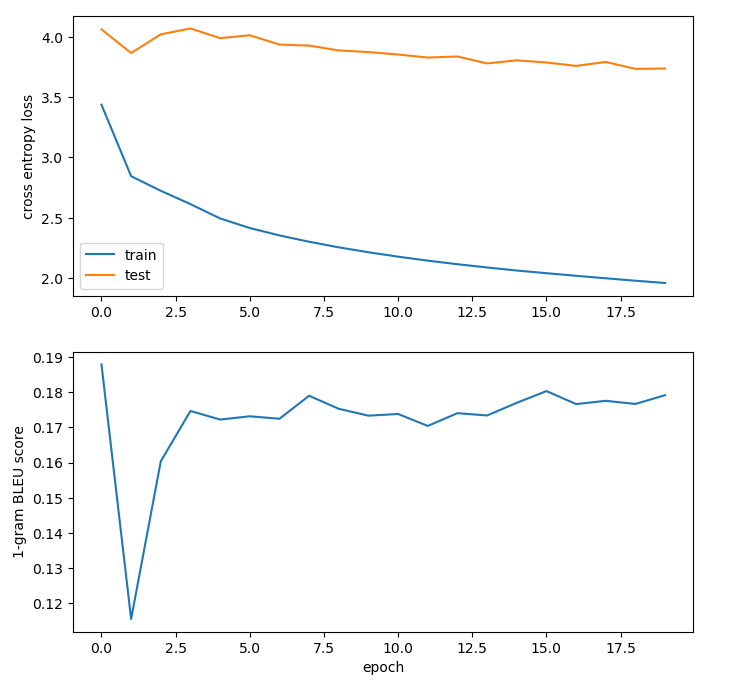
Discussion of results and next steps
Somewhat subjectively, somewhat quantitatively, I decided that the best model fit was the one that used an 80/20 train/test split, a batch size of 256, h=1, N=1, and the Adam parameters described in the paper (second-to-last metrics graph above). I wrote a simple REPL to get english-spanish translations on the fly.
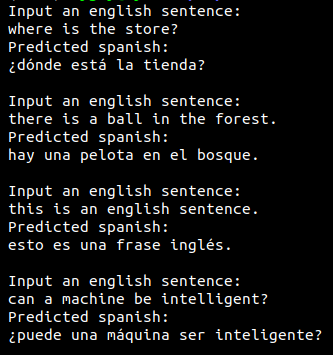
Here's an example of some perfect (when compared to Google translate outputs) translations:
Here are a few translations that contain errors:
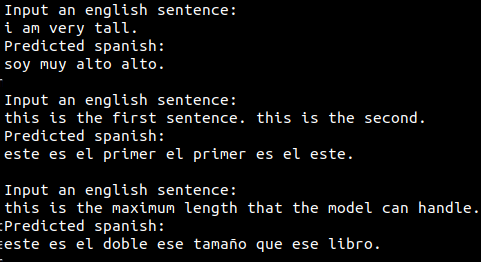
If you don't speak any spanish, the errors in the above example may not be obvious to you. When translated back to english with Google translate, these sentences are:
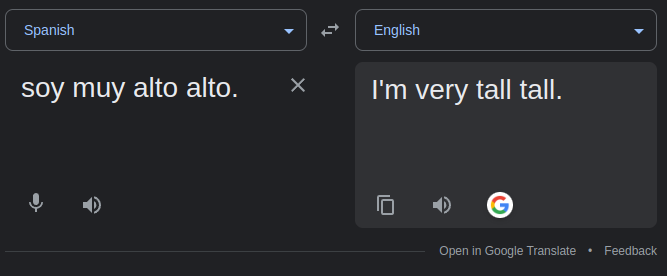
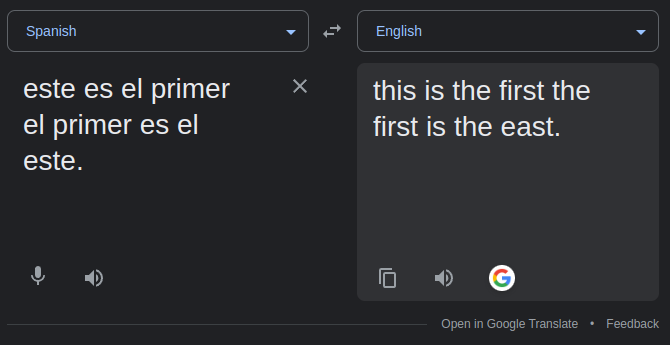
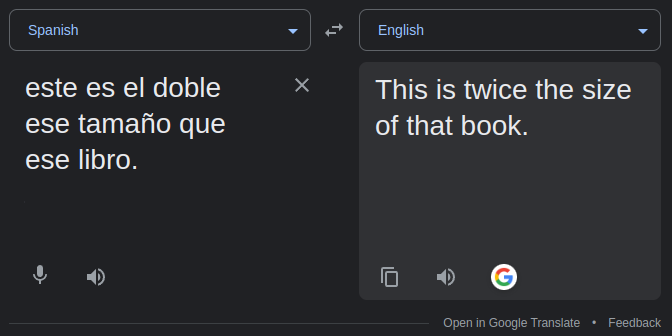
Of course, I can't enumerate every possible translation in the space of the model's possible inputs, but I've tried ~100 translations and have noticed a few general behaviors (these are mostly qualitative observations):
- translations are more likely to be perfect when the input english sentence is a short question or command that contains simple words
- translations are often nearly correct but will contain duplicate words or phrases (see above, for example)
- translations are often nearly correct but will contain incorrect verb conjugation (I'm led to believe that without more context, this is a difficult problem to solve in any translation task)
- punctuation that does not end a sentence is usually ignored (commas may be an exception)
- if punctuation is missing from the input, it will be appropriately added to the end of the output (works with question marks too)
- inputs containing repeated words are handled pretty well, for example "ball ball ball ball ball ball ball ball ball ball ball" will translate to "pelota pelota pelota pelota pelota pelota pelota pelota pelota pelota pelota"
- erroneous translations will sometimes contain words and/or phrases that are conceptually similar to the true concept (this might be the most interesting observation as it displays the power of the attention mechanism)
The end (I hate LLMs)
At this point, all I want to say is that this project was a ton of work and language ML tasks are complicated and I don't want to discuss LLMs anymore.